LCS could be found with using of Generalized Suffix Tree (GST).
Steps to find LCS:
- build generalized suffix tree:
- concatenate original strings;
- build suffix tree.
- calculate special status for each node of the generalized suffix tree:
- original strings labels;
- tree height or suffix length.
- find longest common substring - traverse the tree to find a node with maximal tree height and labeled with all original strings.
Download source code of Longest Common Substring and Diff Implementation.
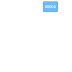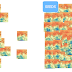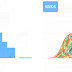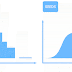
Class diagram:

Helper Inner classes:
- LCSNodeStatus - Suffix Tree Node Status for Longest Common Substring (LCS)
- CommonSubstr - Result of searching Longest Common Substring. Also represents partial diff result.

Node statuses could be calculated:
Map<Node, LCSNodeStatus> statuses = new HashMap<Node, LCSNodeStatus>();
getLCSNodeStatus(suffixTree.getRootNode(), 0, statuses);
where
private LCSNodeStatus getLCSNodeStatus(Node node, int height, Map<Node, LCSNodeStatus> statuses) {
LCSNodeStatus nodeStatus = new LCSNodeStatus(node, height);
if (node.getEdges().size() == 0) {
return nodeStatus;
}
for (Edge edge : node.getEdges()) {
LCSNodeStatus status = getLCSNodeStatus(edge.getEndNode(),
height + getEdgeHeightForNodeStatus(edge), statuses);
status.addString(getEdgeStringNumber(edge));
nodeStatus.mergeStatus(status);
}
statuses.put(node, nodeStatus);
return nodeStatus;
}
Find LCS:
private CommonSubstr getLcs(int beginIndexes[], int endIndexes[], Map<Node, LCSNodeStatus> statuses) {
int max = 0;
int foundBeginIndexes[] = null;
for (LCSNodeStatus status : statuses.values()) {
if ((status.getHeight() > 0) && (status.isAllStrings()) && (max <= status.getHeight())) {
Node node = status.getNode();
int workingBeginIndexes[] = initFoundBeginIndexes();
updateFoundBeginIndexes(beginIndexes, endIndexes, node, status.getHeight(),
statuses, workingBeginIndexes);
if (verifyFoundBeginIndexes(workingBeginIndexes)) {
foundBeginIndexes = workingBeginIndexes;
max = status.getHeight();
}
}
}
if (foundBeginIndexes == null)
return null;
return new CommonSubstr(foundBeginIndexes, max);
}
private int[] initFoundBeginIndexes() {
int beginIndexes[] = new int[texts.length];
for(int i=0; i<texts.length; i++)
beginIndexes[i] = Integer.MAX_VALUE;
return beginIndexes;
}
private void updateFoundBeginIndexes(int beginIndexes[], int endIndexes[], Node node, int height,
Map<Node, LCSNodeStatus> statuses, int[] foundBeginIndexes) {
for (Edge edge : node.getEdges()) {
LCSNodeStatus nodeStatus = statuses.get(edge.getEndNode());
if ((nodeStatus != null) && nodeStatus.isAllStrings()) {
updateFoundBeginIndexes(beginIndexes, endIndexes, edge.getEndNode(),
height + getEdgeHeight(edge), statuses, foundBeginIndexes);
} else {
int stringNumber = getEdgeStringNumber(edge);
int beginIndex = edge.getBeginIndex() - height;
if ((beginIndex < endIndexes[stringNumber]) &&
(beginIndex >= beginIndexes[stringNumber]) &&
(foundBeginIndexes[stringNumber] > beginIndex)) {
foundBeginIndexes[stringNumber] = beginIndex;
}
}
}
}
private boolean verifyFoundBeginIndexes(int[] beginIndexes) {
for(int i=0; i<texts.length; i++)
if (beginIndexes[i] == Integer.MAX_VALUE)
return false;
return true;
}
Diff Implementation:
- find LCS;
- call diff for left part of strings (before LCS);
- call diff for right part of string (after LCS);
- join results.
To define strings search parts 2 arrays are used: beginIndexes[], endIndexes[].
private List<CommonSubstr> diff(int beginIndexes[], int endIndexes[], Map<Node, LCSNodeStatus> statuses) {
CommonSubstr commonSubstr = getLcs(beginIndexes, endIndexes, statuses);
if (commonSubstr == null)
return new LinkedList<CommonSubstr>();
List<CommonSubstr> prev = diff(beginIndexes, commonSubstr.beginIndexes, statuses);
List<CommonSubstr> next = diff(incIndexes(commonSubstr.endIndexes), endIndexes, statuses);
prev.add(commonSubstr);
if (next != null)
prev.addAll(next);
return prev;
}
See also: my other Suffix Trees posts